Machine Learning: Clustering
Announcements
- Assignment 7: Due Wednesday May 18th
- Last class!
Clustering
Clustering
- Clustering is an unsupervised ML method
- Clustering algorithms will attempt to divide a set of data into 2 or more segments
- Data within clusters should be as similar as possible
- Data between clusters should be as different as possible
How can we best draw N boundaries around this data?
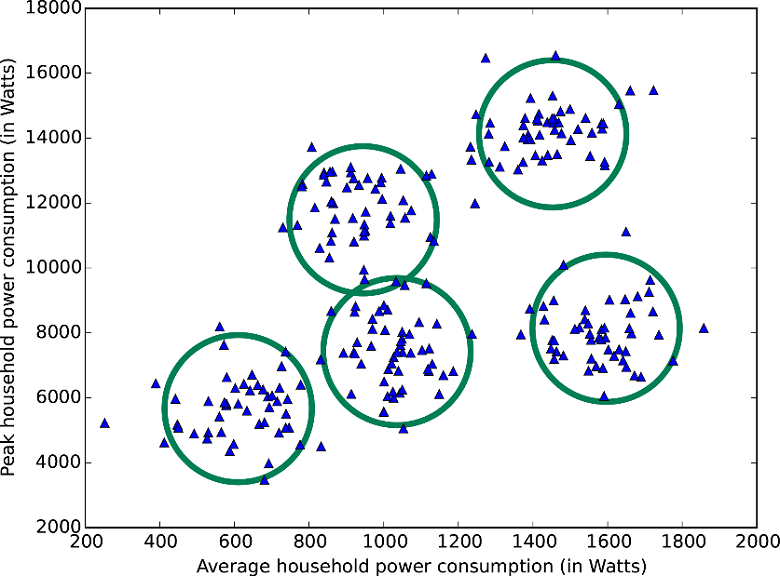
- Most algorithms require you to say how many clusters you want in advance
- But there are also methods to suggest an optimum number of clusters from the data
K-Means Clustering
- Simple, works fairly well
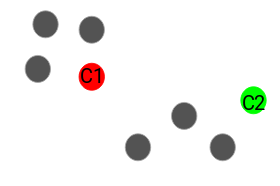
- Pick N random points in your data where N=number of clusters
- Each of these points is called the centroid
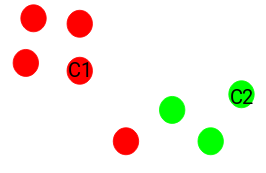
- Go through every other point and assign it to the nearest centroid
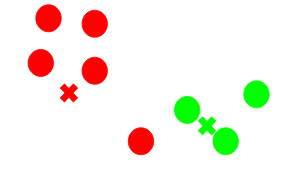
- For each of the clusters, find the new center of the cluster
- Now go through each point and re-assign to the closest centroid
- Keep doing this till the clusters stop changing
Uses of clustering
- Segmentation (audience/customer)
- Document clustering
- Image segmentation
- Recommendation engines
How "well" have we clustered data?
- Common measure: inertia
- To calculate:
- measure the distance between each data point and its centroid
- square this distance
- sum the squares across all points
Let's do some clustering...
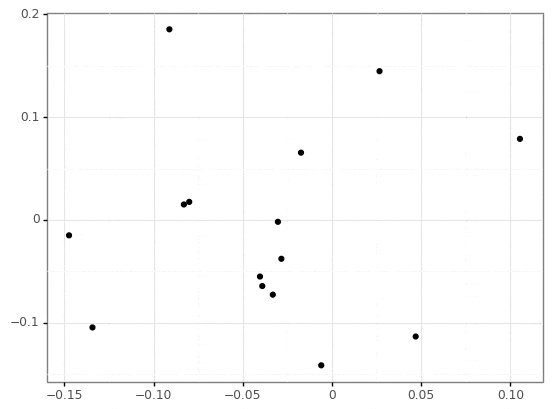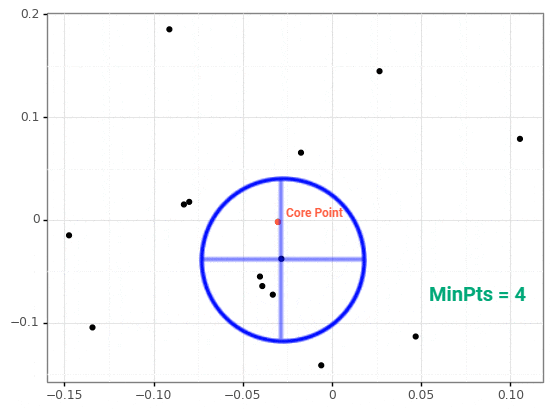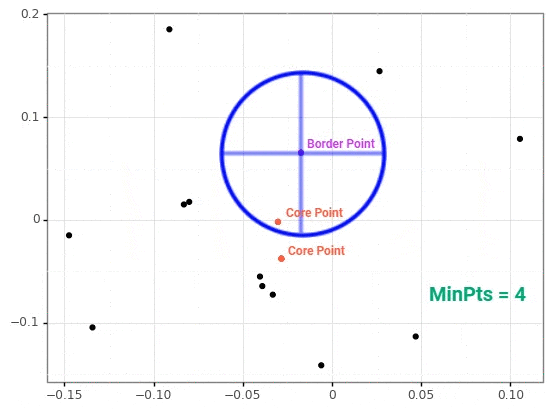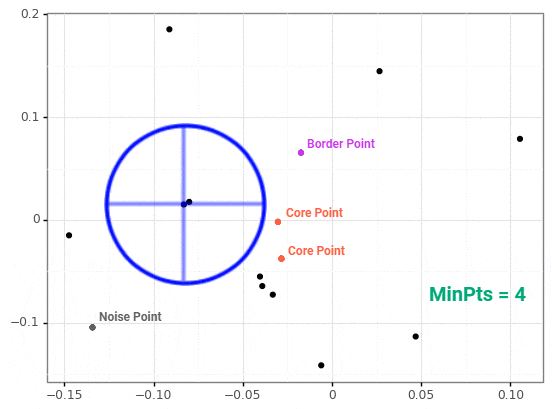
DBSCAN
density-based spatial clustering of applications with noise
k-Means vs. DBSCAN
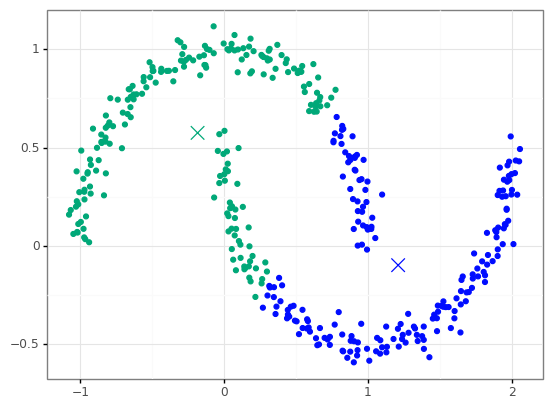
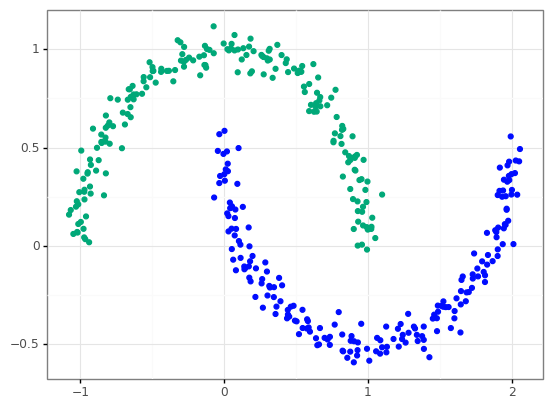
- density - number of points in a circle of specific radius (epsilon)
- minimum points - minimum density for a point to be considered a core point
- core point - points that meet minimum density metric
- border point - points that don't meet minimum density metric but are inside a circle for a core point
- noise - points that are not inside any other circle
Advantages over k-Means
- no need to a priori specify number of clusters in data
- can find clusters of arbitrary shapes
- has a concept of noise, good for data with outliers