Web Scraping
Structured vs. Unstructured Data
- Information is organized in some fashion
- Format is readable by a machine directly
- Examples: CSV, JSON
- Information is not organized in a pre-defined manner
- Designed for humans, not machines.
- Examples: documents, images
Remember, HTML provides a way to add structure and semantic meaning to a document.
It's not exactly structured...but at least semi-structured.
You can manually produce structured
information from semi-structured data.
Let's say I want to create a spreadsheet of the price and customer ratings of cheeses found on gourmetfoodstore.com
The Manual Solution
You could click through evey page of
cheese and manually collect the data.
😞 This will be:
- Slow
- Tedious
- Error-prone
Today we’re going to talking about web scraping:
the practice of automatically extracting
data of interest from webpages into a structured representation.
Python is a great language for doing this.
HTML & CSS: Meet Python 
Web scraping is a two-step process
- Acquire the web page (or pages)
- Extract structured data from the HTML
Acquiring Web Pages
The requests library is an open-source package for downloading web pages with Python
- Python's standard library comes with a module to do this, but it's much harder to use
- Everybody uses requests
pip install requests
Example usage
import requests
response = requests.get("https://cheese.com")
response.text
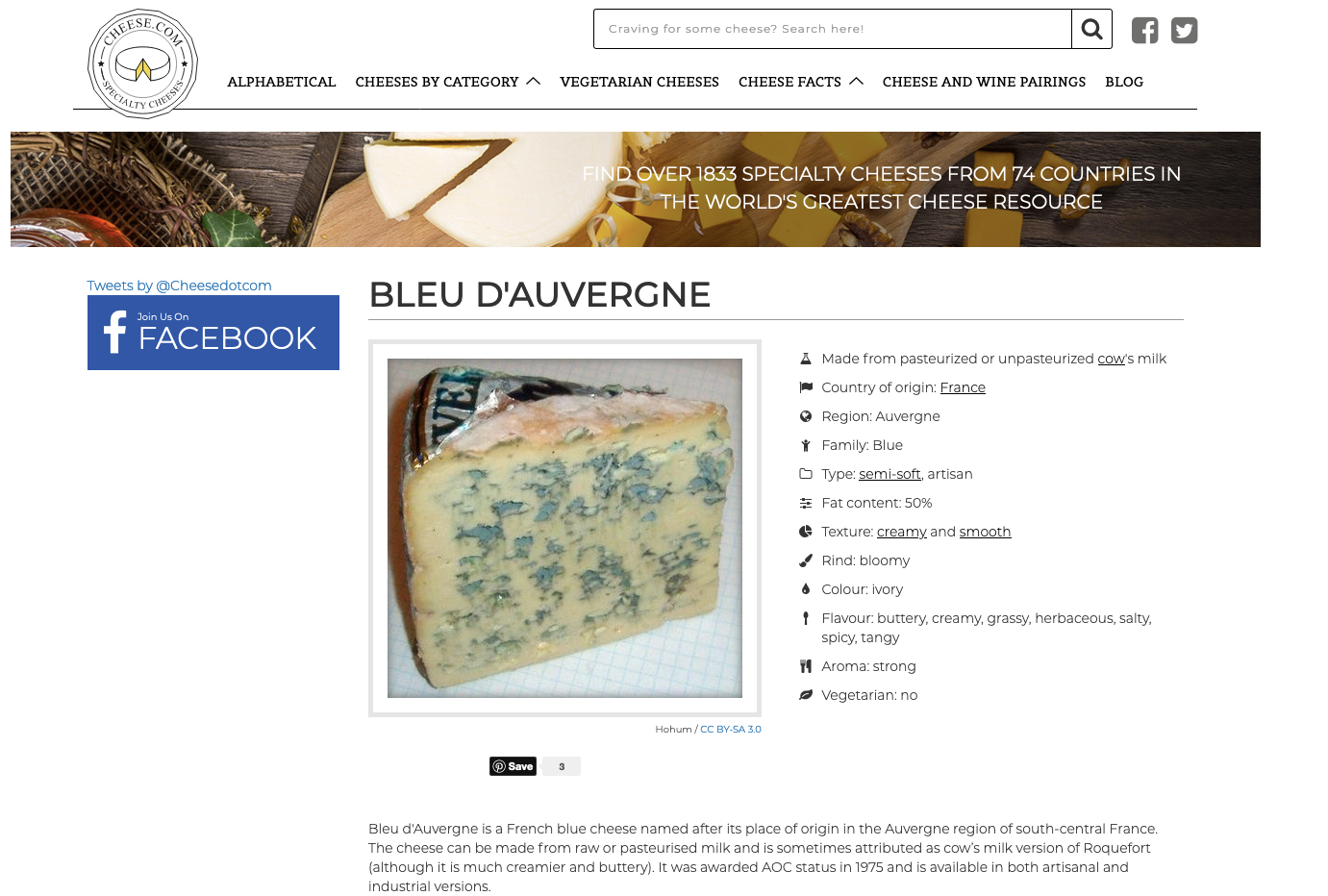
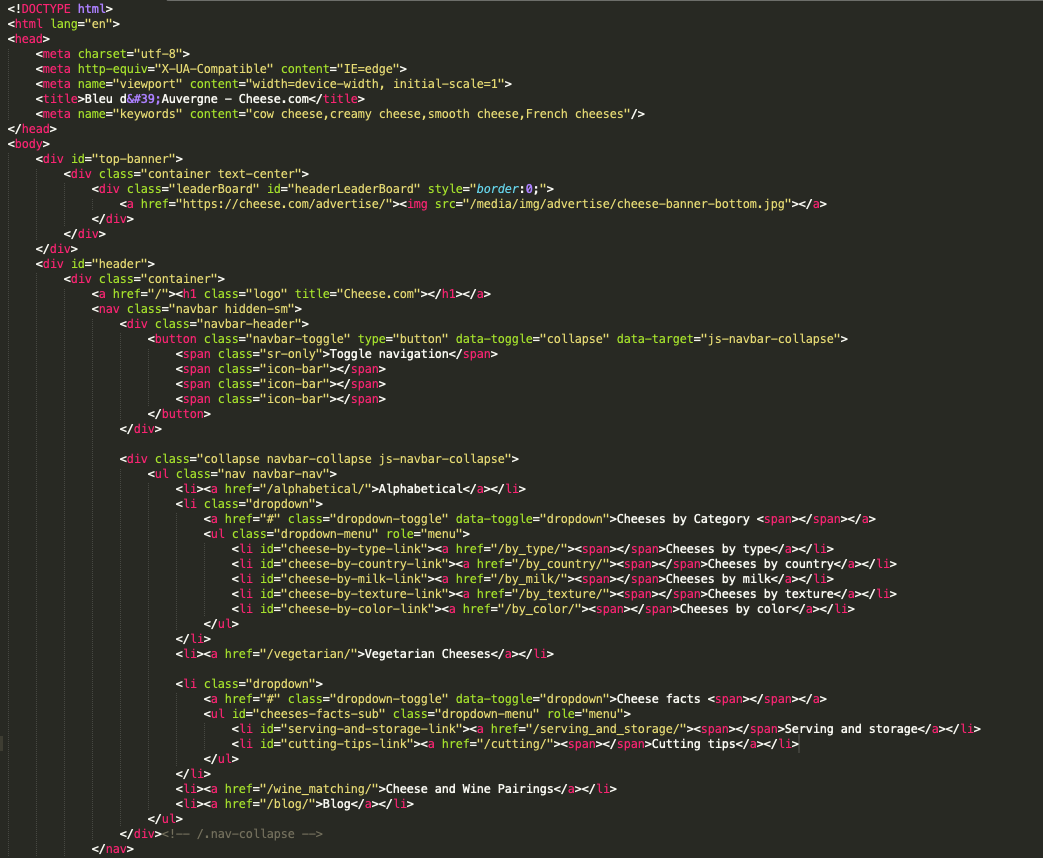
What you get back from
requests.get("https://cheese.com/bleu-dauvergne/").text
...is a huge string representing the HTML of the webpage.
Imagine that you have to use the string manipulation you already know to find all the links on that page and then list where they go.
Kinda scary, right? 😱
Extracting structured data
BeautifulSoup is a scraping library that takes an html string and lets you, the programmer, do “easy” searches for interesting stuff in that string.
- BeautifulSoup can parse an HTML string into a parse tree in much the same way that a web browser does.
- You can search and navigate through this tree to find what you want.
pip install beautifulsoup4
Example usage
import requests
from bs4 import BeautifulSoup
html = requests.get("https://cheese.com/bleu-dauvergne/").text
soup = BeautifulSoup(html, 'html.parser')
How do I use this soup?
So let’s say we still want to find all the links.
(The links are <a> tags in HTML.)
soup.select("a")
[<a href="https://cheese.com/advertise/"><img src="/media/img/advertise/cheese-banner-bottom.jpg"/></a>,
<a href="/"><h1 class="logo" title="Cheese.com"></h1></a>,
<a href="/alphabetical/">Alphabetical</a>,
<a class="dropdown-toggle" data-toggle="dropdown" href="#">Cheeses by Category <span></span></a>,
<a href="/by_type/"><span></span>Cheeses by type</a>,
<a href="/by_country/"><span></span>Cheeses by country</a>,
<a href="/by_milk/"><span></span>Cheeses by milk</a>,
<a href="/by_texture/"><span></span>Cheeses by texture</a>,
<a href="/by_color/"><span></span>Cheeses by color</a>,
...]
What does something like soup.select("a") give you?
- A sequence of tag objects which BeautifulSoup calls a
ResultSet - You can loop over it:
for tag in soup.select("a"): - Or you access it by index:
soup.select("a")[2]
What are each of these things in the ResultSet?
- They are
Tagelements - Each one is a Python object representing an HTML tag and all its descendants.
# will give you a ResultSet with three Tag objects:
soup.select("li")

Remember CSS Selectors?!
.select() understands these.
soup.select("a.nav-links") |
Gets all links with class="nav-links" |
soup.select("#firstHeader") |
Gets the tag with id="FirstHeader" (there can only be one) |
soup.select('[itemprop="name"]') |
Gets all tags with the attribute "itemprop" set to "name" |
soup.select('li a') |
Gets all the links <a> that appear inside of list items <li> |
soup.select('h1, h2, h3') |
Select level 1, 2, or 3 headers |
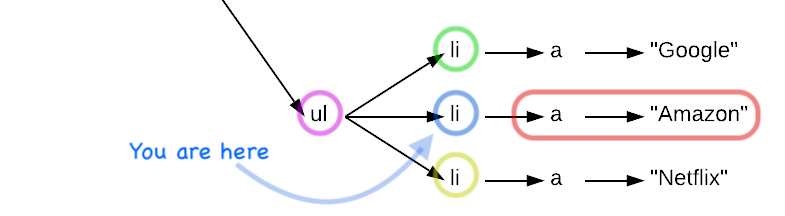
Each Tag object is its own little mini tag soup:
unordered_list = soup.select("ul")[0]
for list_item in unordered_list.select("li"):
for child in list_item.children:
# Each of these is going to an an <a> Tag instance.
Navigating around the HTML tree:
Attributes and Text
Once you get a tag with .select(), you can access its attributes and text.
Here’s an example:
for anchor in soup.select('a'):
print(anchor.text)
if 'href' in anchor.attrs:
print(anchor.attrs['href'])
Notice that .attrs is a dictionary, and we have to make sure that href is in it so we avoid key errors for links
that don’t have href attributes. (It happens, actually. A lot.)
What did that print?
The text of a tag is the text that will actually get put on the webpage that is inside the tag.
The attribute value is whatever appears in the quotes in the tag attributes:
<a href="http://umbc.edu">UMBC </a>
tag.attrs["href"] is "http://umbc.edu"tag.text is "UMBC".
tag.name will be the tag itself. Here that's "a".
Extracting text includes all child tags:
Given this HTML:
<ul>
<li>This is <a href="example.com">link number 1</a>.</li>
<li>This is <a href="example.com">link number 2</a>.</li>
</ul>
This Python:
for li in soup.select("li"):
print(li.text)
...will print "This is link number 1." and "This is link number 2."
In addition to select, you can also use the find method:
first_link = soup.find("a")
email_form = soup.find(id="email-form")
- Find always returns exactly one thing: the first matching element.
- And since it returns one thing, it gives you a
Tagobject instead of aResultSet.
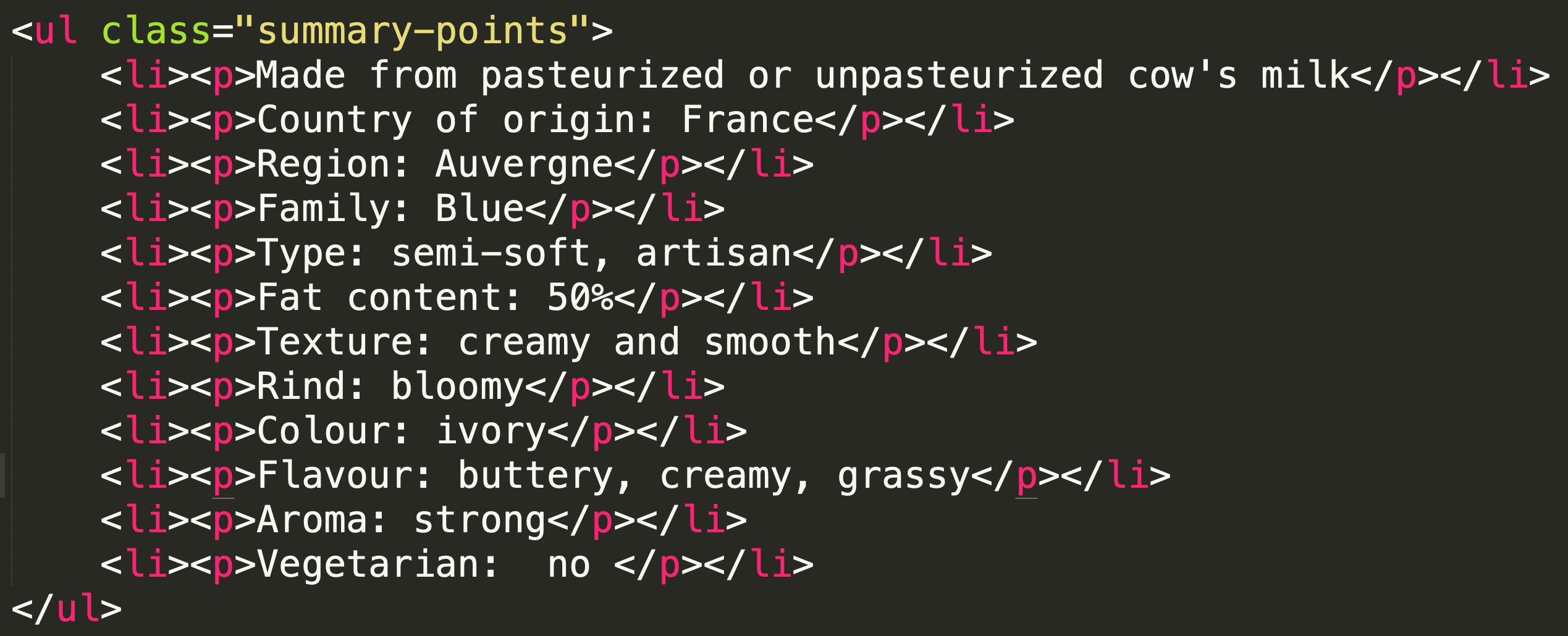
Let's extract these lists from cheese pages:

Here's a page with links to all the cheeses:
Here's the HTML with cheese links:
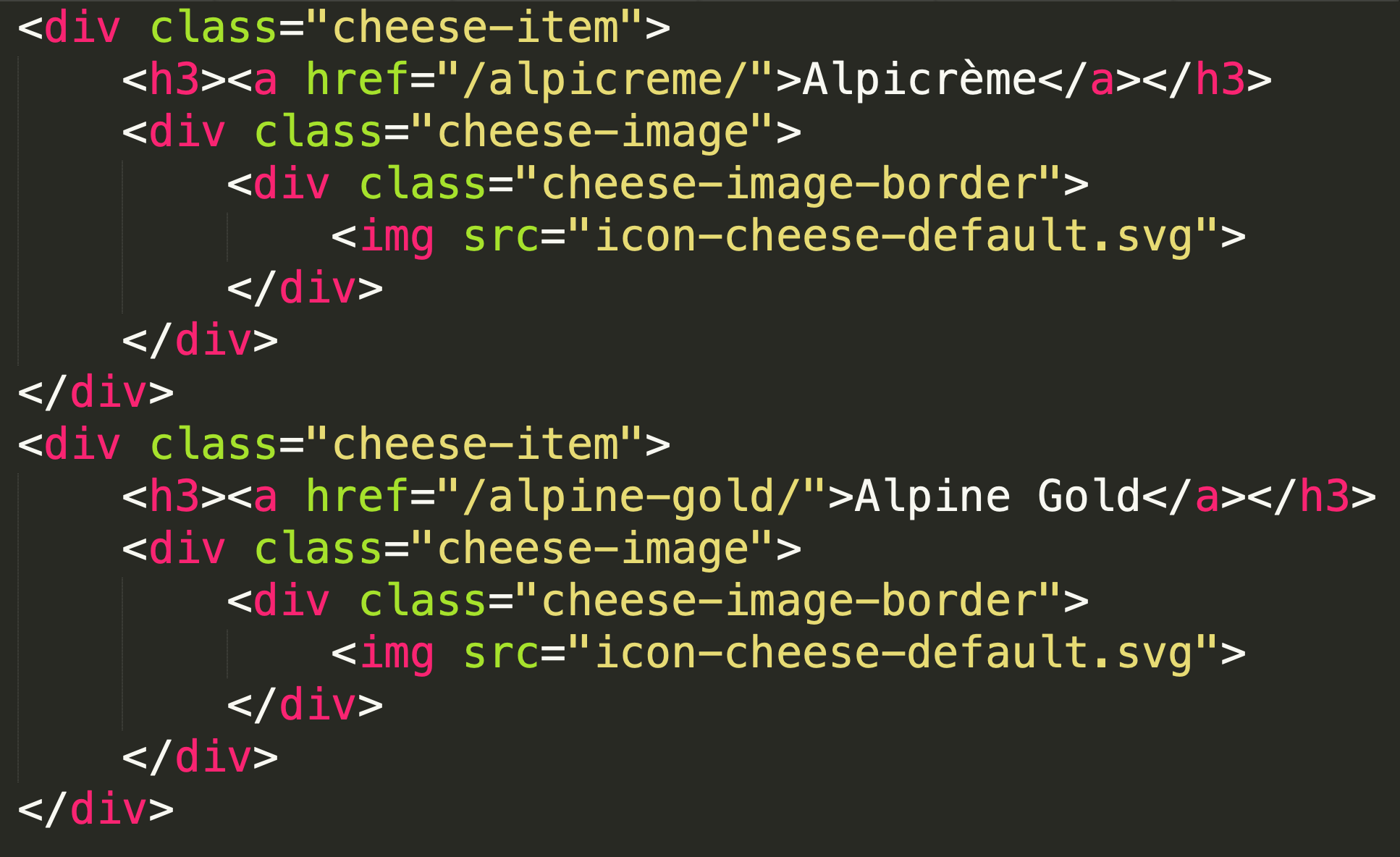
Here's the HTML where the cheese name appears:

Here's the HTML where the cheese properties are: